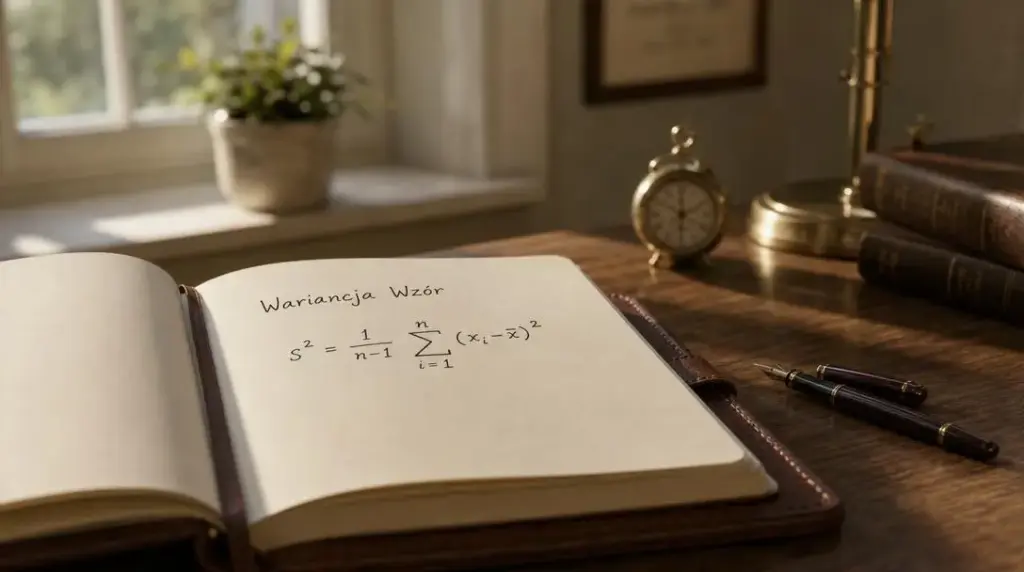
Wariancja to miara rozproszenia danych wokół średniej arytmetycznej. Obliczamy ją jako średnią kwadratów odchyleń poszczególnych wartości od tej średniej. Wzór na wariancję populacji to σ² = (1/N)·Σ(xᵢ-μ)², natomiast dla wariancji próby używa się s² = (1/(n-1))·Σ(xᵢ-x̄)². Mianownik n-1, zwany korektą Bessela, usuwa obciążenie estymatora. Wariancja ma jednostki danych wejściowych podniesione do kwadratu. Jej pierwiastek to odchylenie standardowe, które łatwiej interpretować. W programie Excel wariancję obliczamy funkcjami VAR.P oraz VAR.S.
Wzory na wariancję populacji i próby: najważniejsze różnice
Wzory na wariancję populacji i próby różnią się przede wszystkim mianownikiem. W przypadku populacji dzielimy przez N, czyli liczbę wszystkich elementów, natomiast w próbie stosujemy n-1, co nazywane jest korektą Bessela.
Wariancję populacji (σ²) określamy ze wzoru:. σ² = (1/N) · Σ(xᵢ, μ)²,. Gdzie μ oznacza średnią arytmetyczną całej populacji, a N to liczebność zbioru.
Wariancja próbki (s²) wyraża się wzorem:. S² = (1/(n-1)) · Σ(xᵢ, x̄)²,. Przy czym x̄ to średnia arytmetyczna z próby, a n, liczba elementów w próbce.
Zastosowanie n-1 w mianowniku pozwala poprawić szacunek wariancji. Taka korekta sprawia, że wariancja próby staje się estymatorem nieobciążonym względem wariancji populacji. W praktycznych zastosowaniach, kiedy n jest już spore, na przykład wynosi kilkaset, różnice między obliczeniami obu wzorów stają się znikome i przestają mieć znaczenie.
Wzór na wariancję z populacji
Wariancję populacji obliczamy ze wzoru σ² = (1/N) · Σᵢ₌₁ᴺ (xᵢ, μ)², gdzie:
- σ² oznacza wariancję danej populacji,
- N to liczba wszystkich elementów tej populacji,
- xᵢ reprezentuje poszczególne wartości w zbiorze,
- μ jest średnią arytmetyczną całej populacji.
Symbol σ², czyli sigma do kwadratu, standardowo wskazuje na wariancję populacyjną. Ten wzór stosujemy wtedy, gdy mamy pełne dane obejmujące całą badaną grupę, bez pomijania jakiegokolwiek elementu. Na przykład dla zbioru {2, 4, 4, 4, 5, 5, 7, 9} oraz średniej μ = 5 wariancja populacji wynosi:. σ² = (9 + 1 + 1 + 1 + 0 + 0 + 4 + 16) / 8 = 32 / 8 = 4,0 W mianowniku używamy wartości N, co gwarantuje uzyskanie rzeczywistej średniej kwadratowych odchyleń, a nie tylko przybliżenia.
Wzór na wariancję z próby
Wzór na wariancję z próby wygląda następująco:
S² = (1/(n-1)) · Σi=1n (xi, x̄)², gdzie:
- s² oznacza wariancję próby,
- n to liczba danych w próbie,
- xi wskazuje na poszczególne wartości,
- x̄ to średnia arytmetyczna z próby.
Symbol s² pozwala odróżnić wariancję próby od wariancji populacji, którą zwykle oznaczamy jako σ². Na przykład, rozpatrując dane {2, 4, 4, 4, 5, 5, 7, 9} traktowane jako próba, wariancję obliczamy tak:. S² = 32 / (8-1) = 32 / 7 ≈ 4,5714
Zamiast dzielić przez liczbę obserwacji n, robimy to przez n-1. Dzięki temu wynik jest trochę wyższy niż wariancja populacji. Ta korekta ma na celu uwzględnienie faktu, że wartości w próbie zwykle skupiają się bliżej własnej średniej x̄, a niekoniecznie wokół prawdziwej średniej populacji μ. W konsekwencji wariancja próby jest na ogół większa lub równa wariancji populacji dla tych samych danych.
Krótszy, alternatywny wzór na wariancję populacji
Alternatywna, uproszczona formuła na wariancję populacji to σ² = (1/N) · Σxᵢ², μ². Można ją zapisać również jako σ² = E(X²) – (E(X))². Zamiast obliczać różnicę (xᵢ, μ) dla każdej wartości, najpierw liczymy średnią kwadratów, a potem odejmujemy kwadrat średniej.
To wyrażenie okazuje się szczególnie praktyczne, gdy średnia μ przyjmuje wartości niecałkowite, ponieważ eliminuje konieczność wielokrotnego podnoszenia ułamków do kwadratu, co znacznie upraszcza obliczenia.
Na przykład, dla zbioru {2, 4, 4, 4, 5, 5, 7, 9} obliczamy:
- Średnią kwadratów: E(X²) = (4 + 16 + 16 + 16 + 25 + 25 + 49 + 81) / 8 = 232 / 8 = 29,
- Oraz kwadrat średniej: (μ)² = 5² = 25,
- Dając w efekcie wariancję: σ² = 29, 25 = 4,0.
Uzyskany rezultat jest zgodny z tym, co otrzymujemy, korzystając z klasycznego wzoru. Ta równość wynika z rozwinięcia wyrażenia (xᵢ, μ)², które łączy oba sposoby liczenia wariancji.
Dlaczego we wzorze na wariancję z próby dzielimy przez n-1?
We wzorze na wariancję obliczaną z próby dzielimy przez n-1, a nie przez n, co wynika z tzw. korekty Bessela. To właśnie ona eliminuje błąd systematyczny estymatora.
Gdybyśmy podzielili przez n, otrzymany wynik byłby zaniżony w stosunku do rzeczywistej wariancji populacji. Dzieje się tak, ponieważ wartości w próbie są z reguły bliżej średniej obliczonej z tej próby (x̄) niż od nieznanej wartości średniej populacji (μ).
Wyjaśnia to pojęcie stopni swobody: dla próby składającej się z n elementów pozostaje n-1 stopni swobody, ponieważ jeden „traci się” na wyliczenie średniej x̄. Zastosowanie mianownika n-1 powoduje, że wariancja próby jest nieobciążonym estymatorem wariancji całej populacji, co matematycznie wyraża się wzorem E(s²) = σ². Warto jednak podkreślić, że choć wariancja z próby jest estymatorem nieobciążonym, to odchylenie standardowe tej próby (s) nadal pozostaje obciążone względem odchylenia standardowego populacji (σ).
| Temat | Najważniejsze informacje |
|---|---|
| Różnice między wariancją populacji a próby | Wariancja populacji dzielona przez N (liczba elementów), wariancja próby przez n-1 (korekta Bessela). Korekta n-1 poprawia szacunek wariancji; przy dużej próbie różnice są znikome. |
| Definicje wzorów | Wariancja populacji: σ² = (1/N)·Σ(xᵢ-μ)², μ, średnia populacji. Wariancja próby: s² = (1/(n-1))·Σ(xᵢ-x̄)², x̄, średnia próby. |
| Co mierzy wariancja? | Wariancja mierzy rozrzut danych wokół średniej. Większa wariancja = większe zróżnicowanie. Wariancja jest zawsze ≥ 0, zero oznacza brak rozproszenia (wszystkie dane identyczne). |
| Etapy obliczania wariancji | 1. Oblicz średnią. 2. Oblicz odchylenie każdej wartości od średniej. 3. Podnieś odchylenia do kwadratu. 4. Oblicz średnią z kwadratów (dzieląc przez N lub n-1). |
| Wariancja w Excelu | Funkcje: wariancja populacji,VAR.P, wariancja próby,VAR.S. Automatycznie ignorują tekst i wartości logiczne. Funkcje z uwzględnieniem logiki: VARPA, VAR.SA. |
| Różnica wariancji i odchylenia standardowego | Odchylenie standardowe jest pierwiastkiem wariancji (σ = √σ²). Wariancja ma jednostki podniesione do kwadratu, odchylenie standardowe w tych samych jednostkach co dane. |
| Własności matematyczne wariancji | Var(X) ≥ 0; Var(X + b) = Var(X); Var(aX) = a² · Var(X); Var(aX + b) = a² · Var(X); Var(X + Y) = Var(X) + Var(Y) dla zmiennych niezależnych. |
| Praktyczne zastosowania wariancji | Ocena rozrzutu danych, ryzyko inwestycyjne (wariancja stóp zwrotu), kontrola jakości (ANOVA), wykrywanie overfittingu w uczeniu maszynowym. |
Co mierzy wariancja w zbiorze danych?
Wariancja wskazuje, na jak duży rozrzut danych wokół średniej arytmetycznej możemy liczyć. Im jest większa, tym dane są bardziej zróżnicowane; niższa z kolei świadczy o ich większym skupieniu. Obliczamy ją, biorąc średnią z kwadratów różnic między poszczególnymi wartościami a średnią. Dzięki temu zarówno liczby mniejsze, jak i większe od średniej mają wpływ na ostateczny wynik.
Jeśli wariancja wynosi zero, oznacza to, że wszystkie elementy w zbiorze są identyczne i nie ma żadnego rozproszenia. Warto podkreślić, że ta miara jest zawsze nieujemna (σ² ≥ 0), ponieważ sumujemy kwadraty różnic, a każdy kwadrat liczby rzeczywistej jest nieujemny. Wariancja uwzględnia każde odchylenie od średniej, ale jednocześnie jest bardziej podatna na wpływ wartości odstających (tzw. outliers) niż inne wskaźniki zmienności, jak na przykład rozstęp kwartylowy.
Jakie symbole oznaczają średnią i liczbę obserwacji we wzorze na wariancję?
We wzorze na wariancję populacji σ² = (1/N) · Σ(xᵢ, μ)² symbol μ (grecka litera mi) oznacza średnią arytmetyczną całej populacji. Natomiast N to ogólna liczba obserwacji, czyli wszystkich elementów w populacji.
W przypadku wariancji próby s² = (1/(n-1)) · Σ(xᵢ, x̄)²x̄ (czytane jako „x z kreską”) reprezentuje średnią arytmetyczną tej próby. Liczba n z kolei wskazuje, ile obserwacji zawiera dana próba.
Te różnice w oznaczeniach nie są przypadkowe. Symbol μ i liczba N dotyczą parametrów całej populacji, wartości stałych, choć zwykle nieznanych. Z kolei x̄ oraz n odnoszą się do statystyk wyliczanych na podstawie próby, czyli danych, które posiadamy. Symbol Σ (duża grecka sigma) oznacza sumowanie po wszystkich elementach, od i = 1 do N lub n. Indeks i przechodzi kolejno przez wszystkie obserwacje, a xᵢ to wartość i-tego elementu zestawu danych.
W jakiej jednostce wyrażona jest wariancja w stosunku do danych wejściowych?
Wariancja wyrażana jest w jednostkach będących kwadratem jednostek oryginalnych danych. Na przykład, jeśli wzrost mierzymy w centymetrach, to wynik wariancji będzie podany w centymetrach kwadratowych (cm²). Analogicznie, gdy dane dotyczą masy wyrażanej w kilogramach, wariancja przyjmie postać kilogramów do kwadratu (kg²).
Przykładowo, dla zestawu wzrostów {160, 165, 170, 175, 180} cm, gdzie średnia wynosi 170 cm, wariancja obliczona to 50 cm². Z kolei odchylenie standardowe, które jest pierwiastkiem z wariancji, osiąga wartość około 7,07 cm.
Ponieważ jednostka wariancji to kwadrat jednostki oryginalnej, jej interpretacja bywa mniej intuicyjna w porównaniu do odchylenia standardowego, które zachowuje tę samą jednostkę co dane. Dlatego w praktyce analitycznej częściej sięga się po odchylenie standardowe, podczas gdy wariancja stanowi podstawę do dalszych obliczeń i analiz.
Jak obliczyć wariancję krok po kroku na podstawie wzoru?
Obliczanie wariancji składa się z czterech podstawowych etapów. Na początku wyznaczamy średnią arytmetyczną zbioru danych. Kolejnym krokiem jest określenie, jak bardzo każda wartość różni się od tej średniej. Następnie podnosimy te różnice do kwadratu, a na koniec obliczamy średnią z uzyskanych kwadratów.
Dokładniej:
- 1 oblicz średnią: x̄ = (Σxᵢ)/n,
- 2 wyznacz odchylenie każdej wartości od średniej, czyli (xᵢ, x̄),
- 3 każde odchylenie podnieś do kwadratu: (xᵢ, x̄)²,
- 4 zsumuj wszystkie kwadraty i podziel przez N (jeśli analizujesz całą populację) lub przez n, 1 (w przypadku próby).
Dzięki temu podejściu unikamy problemu neutralizacji odchyleń ujemnych przez dodatnie, co miałoby miejsce przy zwykłym sumowaniu. Kwadraty gwarantują, że każdy rozdźwięk, niezależnie od kierunku, wpływa dodatnio na ostateczną wielkość wariancji, pokazując tym samym prawdziwą rozpiętość danych.
Przykład obliczenia wariancji dla prostego zbioru danych
Dla zbioru danych {2, 4, 4, 4, 5, 5, 7, 9}wariancja populacji wynosi dokładnie 4,0. Możemy to obliczyć w czterech prostych etapach. Krok 1: Najpierw obliczamy średnią μ, dodając wszystkie liczby i dzieląc przez ich ilość: (2 + 4 + 4 + 4 + 5 + 5 + 7 + 9) / 8 = 40 / 8 = 5. Krok 2: Następnie wyznaczamy różnice między każdą wartością a średnią:
2, 5 = -3, 4, 5 = -1, 4, 5 = -1, 4, 5 = -1, 5, 5 = 0, 5, 5 = 0, 7, 5 = 2, 9, 5 = 4 Krok 3: Kolejnym krokiem jest obliczenie kwadratów tych odchyleń:
9, 1, 1, 1, 0, 0, 4, 16;
A ich suma daje 32. Krok 4:Wariancję populacji σ² obliczamy, dzieląc sumę kwadratów przez liczbę elementów: 32 / 8 = 4,0. W przypadku wariancji próby s² dzielimy przez liczbę stopni swobody, czyli 7, co daje około 4,5714. Odchylenie standardowe populacji wynosi σ = √4 = 2,0 cm (lub dowolna inna jednostka). Oznacza to, że dane w zbiorze najczęściej odchylają się od średniej o 2 jednostki. Wynik możemy też potwierdzić, korzystając z alternatywnej metody:
E(X²) – (E(X))² = 29, 25 = 4,0.
Jak obliczyć wariancję dla szeregu rozdzielczego?
Wariancję dla szeregu rozdzielczego oblicza się ze wzoru: σ² = (1/n) · Σᵢ nᵢ·(xᵢ, x̄)², gdzie xᵢ to wartości środkowe przedziałów lub konkretne wartości cechy, nᵢ oznacza liczebność poszczególnych klas, a n = Σnᵢ stanowi sumę wszystkich obserwacji. W przypadku szeregu rozdzielczego przedziałowego zakłada się, że wszystkie dane zawarte w danym przedziale są skoncentrowane w jego punkcie środkowym. Takie uproszczenie niestety wprowadza pewien margines błędu.
Dla przykładowego zestawu danych, wartości środkowe to {10, 20, 30, 40, 50}, a odpowiadające im liczebności wynoszą {3, 5, 8, 4, 2} (łącznie n = 22 obserwacje), średnia ważona obliczona jest na około x̄ ≈ 28,64, a wyliczona wariancja wynosi σ² ≈ 129,96. Najłatwiej przeprowadzić te obliczenia, wykorzystując tabelę, w której dla każdej klasy liczymy iloczyn nᵢ·(xᵢ, x̄)², po czym sumujemy wszystkie wyniki i dzielimy przez całkowitą liczbę obserwacji. Alternatywnie, można skorzystać z innej formuły na wariancję w szeregu rozdzielczym: σ² = (Σnᵢ·xᵢ²)/n, x̄². Dzięki temu podejściu często możemy znacznie uprościć i przyspieszyć obliczenia.
Jak obliczyć wartość oczekiwaną i wariancję zmiennej losowej?
Wartość oczekiwana zmiennej losowej X dla zmiennych dyskretnych wyraża się wzorem E(X) = Σ xᵢ·P(X = xᵢ), który jest sumą iloczynów poszczególnych wartości i odpowiadających im prawdopodobieństw. Natomiast wariancja opisuje rozrzut tych wartości wokół średniej i definiowana jest jako D²(X) = E[(X, E(X))²]. Po odpowiednich przekształceniach wygodniej korzysta się z formy: D²(X) = E(X²) – (E(X))².
Przejdźmy do konkretnego przykładu: zmienna losowa X może przyjmować wartości {-1, 0, 1, 2} z prawdopodobieństwami odpowiednio {0,2; 0,3; 0,3; 0,2}. Wówczas wartość oczekiwana wyliczana jest jako E(X) = (-1)·0,2 + 0·0,3 + 1·0,3 + 2·0,2 = 0,5. Z kolei do obliczenia wariancji potrzebujemy E(X²), które wynosi 1·0,2 + 0·0,3 + 1·0,3 + 4·0,2 = 1,3. Dzięki temu możemy wyznaczyć wariancję: Var(X) = 1,3 – (0,5)² = 1,3, 0,25 = 1,05. Odchylenie standardowe, będące pierwiastkiem z wariancji, przyjmuje wartość σ(X) = √1,05 ≈ 1,025. To właśnie ono pozwala lepiej zrozumieć, jak bardzo rozproszone są wartości zmiennej losowej wokół jej oczekiwanej wartości.
W kontekście rachunku prawdopodobieństwa, wariancja jest miarą zmienności wyników wokół wartości średniej teoretycznej, a nie średniej obserwowanej w konkretnym zbiorze danych z próby. Dzięki temu wskazuje na ogólną niepewność wynikającą z charakteru badanego zjawiska.
Jak policzyć wariancję wykorzystując funkcje w programie Excel?
W Excelu wariancję populacji wyznacza się za pomocą funkcji (luźniej znanej też jako starsza wersja ), natomiast wariancję próby, przy użyciu (lub starszej wariancja). Obie mają identyczną składnię: lub , gdzie zakres_danych to przykładowo zakres komórek A1:A20
Różnica między nimi polega na sposobie dzielenia sumy kwadratów odchyleń, dzieli przez N (liczbę wszystkich elementów), podczas gdy uwzględnia korektę Bessela, dzieląc przez n-1. Oba narzędzia automatycznie ignorują komórki z tekstem oraz wartościami logicznymi (prawda/fałsz). Jeśli zależy nam na uwzględnieniu wartości logicznych jako 1 lub 0, to zamiast nich warto skorzystać z funkcji bądź . Na przykład, dla danych w zakresie A1:A8 formuła obliczy wariancję populacji, a , wariancję próbki, co pozwala uniknąć ręcznych obliczeń i zautomatyzować ten proces.
Czym różni się wariancja od odchylenia standardowego?
Wariancja (σ² lub s²) oraz odchylenie standardowe (σ lub s) opisują to samo zjawisko, rozrzut wartości wokół średniej, choć różnią się pod względem jednostki i formy. Odchylenie standardowe jest pierwiastkiem kwadratowym z wariancji: σ = √σ², dzięki czemu wyrażone jest w tych samych jednostkach, co dane.
Wariancja posiada jednostki podniesione do kwadratu. Na przykład, jeśli mierzysz długości w centymetrach, to odchylenie standardowe będzie miało jednostkę centymetrów, natomiast wariancja, centymetrów kwadratowych.
Weźmy pod uwagę zbiór {2, 4, 4, 4, 5, 5, 7, 9}, jego wariancja populacji wynosi σ² = 4,0 (w jednostkach kwadratowych), a odchylenie standardowe σ = 2,0 (w jednostkach odpowiadających danym). Ze względu na różnicę w wymiarach, odchylenie standardowe łatwiej zinterpretować na pierwszy rzut oka. Pokazuje ono typową odległość wartości od średniej, zachowując oryginalną skalę pomiarową. Z kolei wariancja lepiej sprawdza się w kontekście matematycznych analiz i wzorów, gdyż posiada prostsze własności algebraiczne, na przykład sumowalność dla zmiennych niezależnych.
Jakie są najważniejsze własności matematyczne wariancji?
Wariancja ma kilka istotnych własności matematycznych, które są fundamentem dla dalszych analiz statystycznych. Przede wszystkim, nigdy nie przyjmuje wartości ujemnej: Var(X) ≥ 0. Wariancja jest równa zero tylko wtedy, gdy zmienna X jest stała, czyli wszystkie jej obserwacje mają tę samą wartość.
Kolejną cechą jest niezmienność wariancji względem przesunięcia:Var(X + b) = Var(X) dla dowolnej stałej b. Oznacza to, że dodanie stałej do każdego elementu zbioru nie wpływa na rozproszenie danych.
Wzrost lub zmniejszenie rozrzutu następuje natomiast przy skalowaniu zmiennej. Wariancja zmienia się według wzoru: Var(aX) = a² · Var(X). To znaczy, że pomnożenie wszystkich wartości przez liczbę a skutkuje mnożeniem wariancji przez kwadrat tej liczby. Na przykład, jeśli a = 3 oraz Var(X) = 4, to wynik wyrażenia Var(3X) = 9 · 4 = 36.
Łącząc przesunięcie i skalowanie, otrzymujemy wzór:Var(aX + b) = a² · Var(X). Warto także zwrócić uwagę na addytywność wariancji dla zmiennych niezależnych, co wyraża się wzorem:Var(X + Y) = Var(X) + Var(Y). Jeśli X i Y są zależne, dochodzi dodatkowy składnik związany z kowariancją. Dzięki tej właściwości, wariancja sumy n niezależnych zmiennych o tej samej wariancji σ² przyjmuje wartość n · σ², co jest podstawą pod Centralne Twierdzenie Graniczne.
Do czego praktycznie wykorzystuje się wariancję w analizie danych?
Wariancja stanowi podstawowe narzędzie wykorzystywane w analizie danych, finansach, kontroli jakości oraz naukach badawczych. Umożliwia ona ocenę, jak bardzo obserwacje odbiegają od średniej wartości.
W statystyce opisowej wariancja odzwierciedla jednorodność badanej próby. Na przykład, jeśli wyniki egzaminów cechuje niska wariancja, świadczy to o zbliżonym poziomie wiedzy uczniów, natomiast wysoki jej poziom wskazuje na duże rozpiętości w wynikach.
W sferze finansów wariancja stóp zwrotu pełni funkcję wskaźnika ryzyka inwestycyjnego. Teoria portfelowa opracowana przez Markowitza w 1952 roku opiera się na dążeniu do minimalizacji wariancji przy założonym oczekiwanym zysku, co pozwala efektywnie zarządzać portfelem, godząc zysk z ryzykiem.
W kontekście kontroli jakości analiza wariancji (ANOVA) służy do oceny, czy różnice pomiędzy grupami produktów, na przykład wytwarzanych przez różne maszyny lub na różnych zmianach, mają charakter statystycznie istotny, czy są jedynie efektem losowych fluktuacji. W dziedzinie uczenia maszynowego wariancja błędu predykcji sygnalizuje problem nadmiernego dopasowania modelu do danych treningowych, znany jako overfitting. Oznacza to, że model zbyt dokładnie odwzorowuje dane uczące, co przekłada się na gorszą skuteczność przy generowaniu prognoz na nowych, nieznanych zbiorach danych.
Jak prawidłowo interpretować wynik wariancji?
Wynik wariancji powinien być zawsze oceniany w odniesieniu do skali oraz jednostki miary danych. Samo liczbowo podane wartości bez kontekstu niewiele mówią na temat rozproszenia danych.
Przykładowo, jeśli wariancja wynosi 4 cm² dla wzrostów około 170 cm, oznacza to niewielkie rozrzucenie, ponieważ odchylenie standardowe to 2 cm. Z kolei ta sama wartość 4 będzie niemal niezauważalna przy cenach akcji w przedziale od 10 do 1000 zł. Aby lepiej zrozumieć rozkład danych, często przelicza się wariancję na odchylenie standardowe, czyli pierwiastek kwadratowy z wariancji. Ta miara ma tę samą jednostkę co dane i pokazuje przeciętne odchylenie wartości od średniej.
Kolejnym etapem analizy jest porównanie wariancji w różnych zestawach danych,wyższa wartość, zarówno σ², jak i s², świadczy o większym rozproszeniu.
W statystyce inferencyjnej ocena istotności wariancji odbywa się za pomocą:
- Testu chi-kwadrat w przypadku jednej próby,
- Testu F, gdy porównujemy dwie próby.
Dzięki tym metodom można stwierdzić, czy zaobserwowane zróżnicowanie jest efektem losowości, czy faktyczną cechą badanej populacji.